미국의 AI 연구소, DeepSeek를 능가하는 새로운 AI 모델 발표
최근 미국 시애틀에 위치한 비영리 AI 연구 기관인 Ai2 (Allen Institute for AI)에서 주목할 만한 소식이 들려왔습니다. 바로 DeepSeek (딥씨크) 사의 최고 시스템 중 하나인 DeepSeek V3를 능가한다고 주장하는 새로운 AI 모델, Tulu 3 405B (툴루 3 405B)를 공개한 것입니다.
Tulu 3 405B, 주요 AI 벤치마크에서 GPT-4o까지 앞서
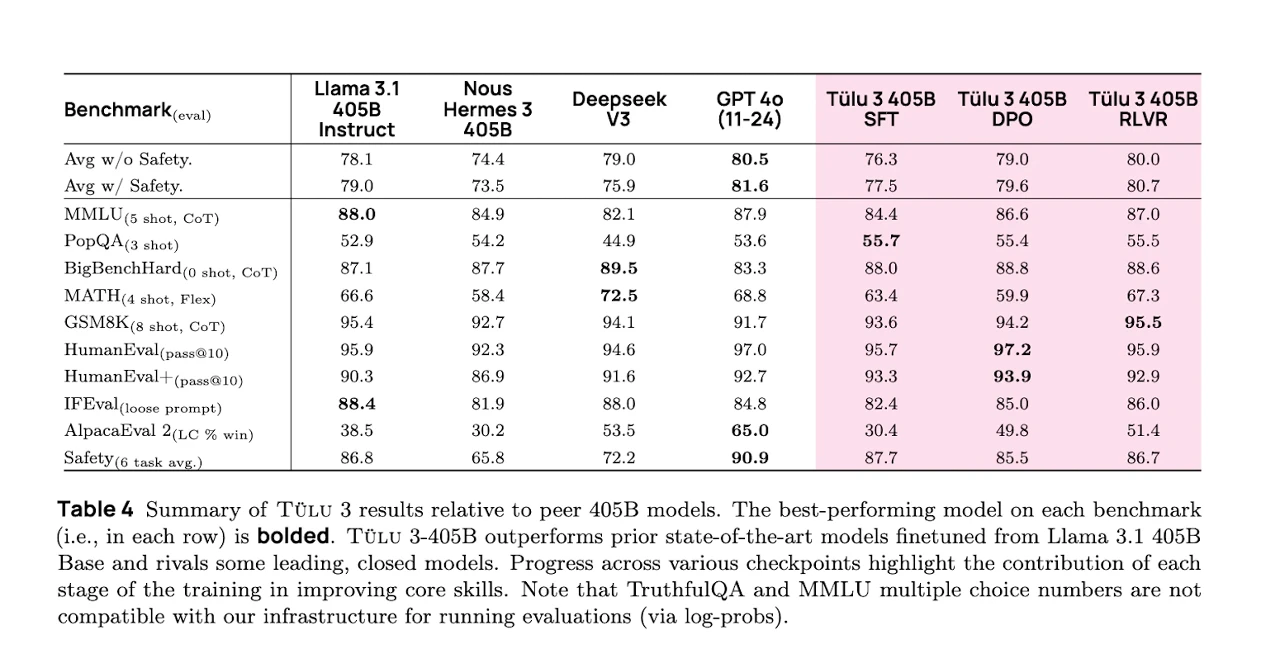
Ai2의 자체 테스트 결과에 따르면, Tulu 3 405B는 DeepSeek V3뿐만 아니라 OpenAI (오픈AI)의 GPT-4o 모델보다 특정 AI 벤치마크에서 더 뛰어난 성능을 보인다고 합니다. 특히 Tulu 3 405B의 가장 큰 특징은 GPT-4o는 물론 DeepSeek V3와 달리 오픈 소스라는 점입니다. 이는 모델을 처음부터 재현하는 데 필요한 모든 구성 요소가 자유롭게 이용 가능하며, 허용적인 라이선스하에 제공된다는 의미입니다.
Ai2 대변인은 Tulu 3 405B 모델이 “최고 수준의 생성형 AI 모델의 글로벌 개발을 주도할 수 있는 미국의 잠재력을 강조한다”고 밝혔습니다. 또한, “이번 발표는 경쟁력 있는 오픈 소스 모델 분야에서 미국의 리더십을 강화하며, 오픈 AI의 미래에 중요한 순간”이라고 덧붙였습니다. 더불어 “Ai2는 이번 모델 출시를 통해 DeepSeek 모델에 대한 강력한 미국 개발 대안을 제시하며, AI 개발뿐만 아니라 미국이 거대 기술 기업에 의존하지 않고도 경쟁력 있는 오픈 소스 AI를 주도할 수 있음을 보여주는 중요한 전환점을 만들었다”고 강조했습니다.
4050억 개의 파라미터, 강화 학습으로 성능 향상
Tulu 3 405B는 4050억 개의 파라미터를 가진 대규모 모델입니다. Ai2에 따르면, 이 모델을 훈련하는 데 256개의 GPU가 병렬로 사용되었다고 합니다. 일반적으로 파라미터 수는 모델의 문제 해결 능력과 비례하며, 파라미터가 많을수록 성능이 향상되는 경향이 있습니다.
Ai2는 Tulu 3 405B가 경쟁력 있는 성능을 달성한 주요 요인 중 하나로 ‘검증 가능한 보상을 활용한 강화 학습 (Reinforcement Learning with Verifiable Rewards, RLVR)’ 기술을 꼽았습니다. RLVR은 수학 문제 해결이나 명령어 따르기와 같이 “검증 가능한” 결과가 있는 과제를 통해 모델을 훈련시키는 방식입니다.
PopQA 및 GSM8K 벤치마크에서 최고 성능 기록
Ai2의 주장에 따르면, Wikipedia (위키피디아)에서 추출한 14,000개의 전문 지식 질문 세트인 PopQA 벤치마크에서 Tulu 3 405B는 DeepSeek V3, GPT-4o는 물론 Meta (메타)의 Llama 3.1 405B 모델까지 모두 능가하는 성능을 보였습니다. 또한, 초등학생 수준의 수학 단어 문제 테스트인 GSM8K에서도 동급 모델 중 가장 높은 성능을 기록했습니다.
현재 Tulu 3 405B는 Ai2의 챗봇 웹 앱을 통해 직접 테스트해 볼 수 있으며, 모델 훈련 코드는 GitHub (깃허브)와 AI 개발 플랫폼 Hugging Face (허깅 페이스)에서 공개되어 있습니다. 새로운 AI 챔피언의 등장이 앞으로 AI 기술 발전에 어떤 영향을 미칠지 기대가 됩니다.