xAI, Grok 3 벤치마크 결과 논란: 과장 광고일까?
최근 인공지능(AI) 벤치마크와 관련된 논쟁이 뜨겁습니다. 특히 AI 연구소들이 벤치마크 결과를 발표하는 방식에 대한 비판의 목소리가 커지고 있어요.
이번 주에는 OpenAI의 한 직원이 일론 머스크의 AI 회사인 xAI가 최신 AI 모델인 Grok 3의 벤치마크 결과를 오도했다는 의혹을 제기했습니다. 이에 대해 xAI의 공동 창립자인 이고르 바부시킨(Igor Babushkin)은 회사가 옳았다고 주장하며 논쟁이 시작되었죠.
논란의 중심: AIME 2025 벤치마크
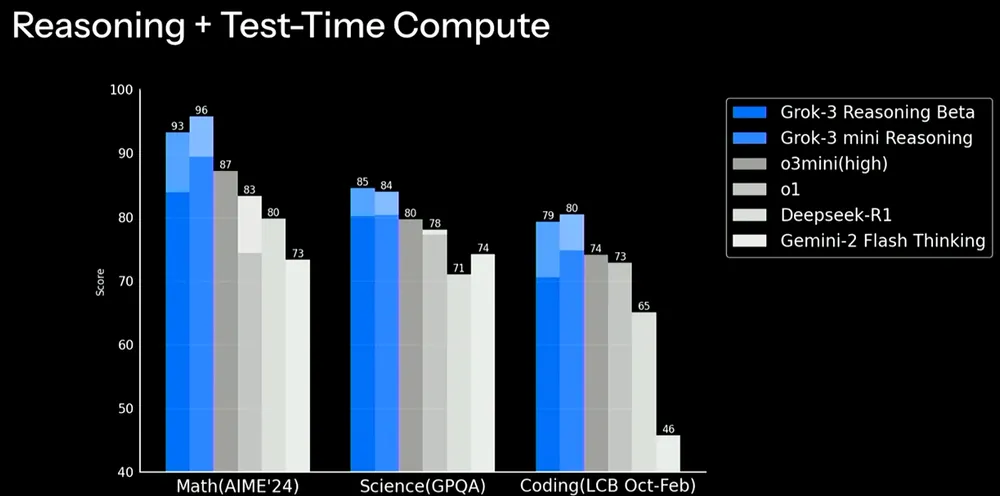
xAI는 최근 AIME 2025 벤치마크에서 Grok 3의 성능을 보여주는 그래프를 공개했습니다. AIME(American Invitational Mathematics Examination)는 어려운 수학 문제들로 구성된 시험으로, AI 모델의 수학 능력을 평가하는 데 자주 사용됩니다.
xAI의 그래프는 Grok 3의 두 가지 버전인 Grok 3 Reasoning Beta와 Grok 3 mini Reasoning이 OpenAI의 최고 성능 모델인 o3-mini-high를 AIME 2025에서 능가한다고 보여줬습니다. 하지만 OpenAI 직원들은 xAI의 그래프가 “cons@64″에서의 o3-mini-high의 AIME 2025 점수를 포함하지 않았다고 지적했습니다.
cons@64란 무엇일까요?
“cons@64″는 “consensus@64″의 줄임말로, 모델이 벤치마크의 각 문제에 대해 64번의 시도를 할 수 있도록 하고, 가장 자주 생성된 답변을 최종 답변으로 선택하는 방식입니다. 당연히 cons@64는 모델의 벤치마크 점수를 상당히 높이는 경향이 있습니다. 따라서 그래프에서 이를 생략하면, 실제로는 그렇지 않음에도 불구하고 한 모델이 다른 모델을 능가하는 것처럼 보이게 할 수 있습니다.
Grok 3 Reasoning Beta와 Grok 3 mini Reasoning의 AIME 2025 점수는 “@1”, 즉 모델이 벤치마크에서 얻은 첫 번째 점수로, o3-mini-high의 점수보다 낮습니다. Grok 3 Reasoning Beta는 OpenAI의 모델보다 약간 뒤쳐져요. 하지만 xAI는 Grok 3를 “세계에서 가장 똑똑한 AI”라고 홍보하고 있습니다.
과거에도 유사한 사례가 있었다?
바부시킨은 과거에 OpenAI도 자사 모델의 성능을 비교하는 차트에서 이와 유사하게 오해를 불러일으킬 수 있는 벤치마크 차트를 게시한 적이 있다고 주장합니다. 논쟁에서 중립적인 입장을 취한 한 관계자는 거의 모든 모델의 cons@64에서의 성능을 보여주는 더 “정확한” 그래프를 만들었습니다.
AI 연구원 네이선 램버트(Nathan Lambert)가 지적했듯이, 가장 중요한 지표는 각 모델이 최고의 점수를 달성하는 데 드는 계산 비용(및 금전적 비용)일 수 있습니다. 이는 대부분의 AI 벤치마크가 모델의 한계와 강점에 대해 얼마나 적은 정보를 제공하는지 보여줍니다.
결국, AI 모델의 성능을 정확하게 평가하고 비교하는 것은 매우 복잡한 문제입니다. 벤치마크 결과는 참고 자료로 활용하되, 맹신하기보다는 다양한 요소를 고려하여 판단하는 것이 중요합니다.